Chi-Loong, Updated 1st May 2020
Since the Covid19 pandemic upended billions of lives around the world, we have had some really gorgeous simulations / visualizations to explain how an infection spreads.
Here are some links to posts and stories that you might have seen:
Washington Post: Why outbreaks like coronavirus spread exponentially, and how to “flatten the curve” (by Harry Stevens)
Simulating an epidemic (by 3Blue1Brown, Grant Sanderson)
Outbreak (by Kevin Simler)
Being stuck at home in Singapore on a lockdown (which was just extended to another month), I wanted a project to occupy my time.
And I had a different take on simulating and visualizing a virus outbreak in a town.
Instead of people moving about randomly, I felt that giving people a routine home to work to home cycle seemed more realistic to me. Was there a way I could show this, and what insights could we draw?
So I coded up my own model for fun that people can play and explore.
Please note that my toy model is just that: A fun thought experiment.
It is highly simplified and the simulation rules do not represent real life at all with all its complexities.
You simplify things to communicate ideas, but this is in no way a real epidemological model.
I do not have a background in epidemology and neither am I a doctor. So please defer to these experts, like we all should. If I have gotten anything wrong, it is entirely my own fault. Do let me know if you spot any errors!
What I do is visualization work to communicate stories and ideas. And I see code as a tool and way to share my ideas.
Here’s our very simplified base toy model.
Let’s assume that we have a small town with about 150 people that lives in it.
In this town, there are 50 homes (![]() ) and 30 workplaces (
) and 30 workplaces (![]() ). The people in town are randomly assigned to one permanent home and one permanent workplace.
). The people in town are randomly assigned to one permanent home and one permanent workplace.
Everybody has a schedule – they either are at work from 9am to 5pm, or they are at home.
The simulation starts with one sick individual on Day 0 at 12 midnight (and thus everybody is at home). Everyone is at home till 9am in the morning, at which everyone goes to work.
Every person is represented by a dot. If you’re healthy you’re black. Else, if you’re sick and infectious, you’re red.
Every hour, every sick person has a chance to infect every other non-sick person at the same location. Thus when you have more sick people at a location, the risk for healthy folks get compounded.
Travel from location to location is instant and no one gets infected during movement.
Based on this model, let’s try running the simulation and see how it works!
Please run these simulations / visualization on a modern browser. Also, although this will work for mobiles, this will look a lot better for desktops and bigger tablets, because a bigger canvas allows for the town simulation to be bigger.
Our model here is rather simple, and it is just about infection. It does not take into account any resistance or anything like that. But even in this barebones state the visualization can help with intuitions about viral spread.
You might notice a few things if you run the simulation a few times:
You might get lucky and the number of sick is really low after several days. Perhaps you got a good randomized start, and the sick individual lived alone, and the workplace he or she worked in had very few employees.
Once you start having a small base of people who are sick, it likely and quickly starts to explode as people move around and spread.
The number of homes and workplaces gives you an idea of how spread out a population is. The more spread out a population is, the less chance they have to interact.
If you group a bunch of people at one same location, it is likely to become a vector of spread, and one infection will likely quickly multiply at that location and spread it all throughout the town.
The last point may be a a common sense intuition, but becomes clear when visualized.
For example, in Singapore our current lockdown situation is due to Covid19 spread in migrant workers who were squeezed into a few dormitories. For them it is extremely difficult to isolate, and thus when the virus started to circulate, it exploded.
Another example: Having one main employer in town like a meat-packing factory. If you get one case in town, it is likely to spread.
You can see these intuitions better by putting more people in less homes and workplaces when you run the simulation. One red dot quickly becomes a bunch of angry red dots at chokepoints.
Each simulation run gets outcomes based on chance.
If you get lucky in your run, you might not get that much infection. Conversely, you could be unlucky and see the whole town get sick before the simulation time even ran out.
Actually this is somewhat similar to real-life: Luck does play a part in epidemics on who and where it strikes, and how it grows and dies in any particular place.
In real life, we only live in this one timeline, and we only see the case results after infections have occured. If we got lucky, we may think that the virus is not as serious or contagious.
The trouble is that whilst your town (or you individually) may not be as affected, the overall trend is that many other towns (and other people) would have gotten an unlucky dice roll.
Our trouble as humans is that we tend to only see localized events, and mistake it for the entire trend.
Our cognitive biases makes it hard to fight long-term, complex challenges like Covid19 (looking like this is going to be more and more likely) or climate change because we evolved to pay attention to short-term immediate problems.
In any case, in simulation land, because it is a thought experiment, we can do something that cannot be done in real-life: We can rerun the simulation thousands of times, and plot the results to get the most probable outcomes.
If we keep everything the same except for changing one parameter, we can get useful conclusions.
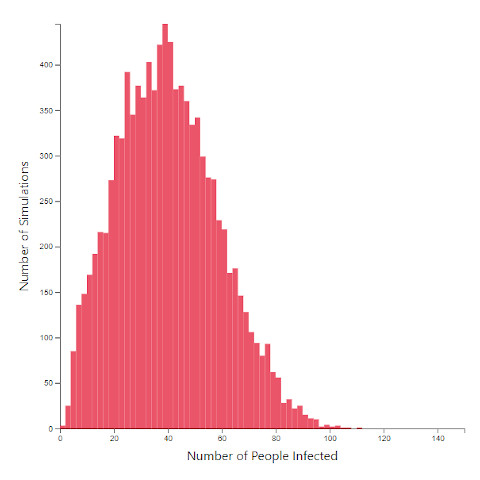
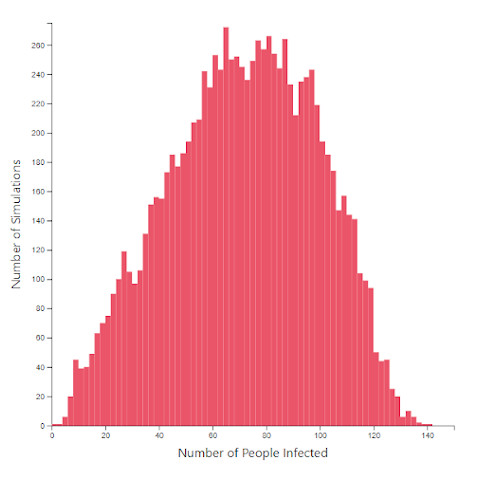
Parameters: 150 people town, 50 homes, 3 days simulation time, 2% infection rate.
Everything is the same except for number of workplaces.
Both scenario simulations run 10,000 times.
I considered making this interactive for readers, but dropped the idea as it is compute heavy and takes time to run.
What you are looking at is the number of infections at the end of 3 days plotted in 2 histograms (bar chart) after 10,000 simulations for each scenario. The only change is the number of workplaces.
You can see that the average number of infections is less in the 30 workplaces scenario compared to the 20 workplaces one, even without calculating the exact mean / median / variance.
Feel free to skip this section if you're not into statistics or code as it delves into some fun technical ideas.
A quick detour. If you plot many independent random variables (due to the Law of Large Numbers), you will get a nice bell curve due to the Central Limit Theorem. Just like here!
This, in essence, is why data polling is such a powerful tool and why it works to tell us about the sampled population.
But hold on, you might ask. If I run your simulation with randomized data, I will get a different result, right?
Correct. This is why for all these charts, for reproducibility, it is run based on a specific psuedo number generator (PRNG) algorithm running on a specific hash.
The default javascript Math.random() does not provide for this. The random numbers generated here are based on the SFC2 algorithm (here is a great list).
In any case, if you have an interest in reproducing these results, you can checkout and play with the code in the github repository.
Now that we have a baseline model to work with, let’s explore some other scenarios.
This article is a work in progress and I will add more models over time.
For example, how do quarantine breakers affect infection rates? Under a lockdown, how does the percentage of essential businesses affect infection?
What if people have different types of schedules? Or if social activities are allowed, and people are allowed to mix around at social places after social distancing is in effect? Can we model this?